# Packages
# README
Syncer
A simple change data capture (CDC) processing library for postgres based on DBLog.
Problem Statement
Popular databases emit events when the data they store are mutated in someway (eg created, updated, deleted etc). These events are popularly knows as change data capture (CDC) events. Postgres - a very popular open source database vendor is not a stranger to CDC. It provides CDC through a process Logical Decoding using Replication Slots. Replication slots are the queue/stream of changes that are stored and can be read and replayed by a consumer in the same order as they were made. The basic concept is something like:
[ Source DB] ---> [ one or more Replication Slots ] ---> [ Reader/Poller ] ----> [ Processed Output ]
- The source DB emits change events via replication slots (RS) which are persisted on disk
- The reader polls/reads the change events from the slot.
- Each replication slot has an "offset" associated which is a pointer to the last unprocessed event (as indicated by the reader).
- The reader once it processes a event can "forward" the offset to point to the next event. Once the offset is updated, events "before" this offset cannot be read again.
- If the reader forwards the offset before processing events then we have at-most-once guarantees on event processing. If the reader crashes after forwarding the offset but before processing it then the events are lost.
- If the reader forwards the offset AFTER processing events then we have at-least-once guarantees on event processing. If the reader crashes after successfully processing a event but before forwarding the offset then the reader is suscepting to reading the same event again and re-processing it.
- Exactly once processing is left to the reader (of this doc) and can never be (easily) guaranteed.
This kind of processing of change events has several practical uses:
- Data Replication/Synchronization: With CDC replication of databases across different environments is enabled (eg production <-> data warehouse, creation of secondry indexes etc). This can also include use cases like incremental backups - where capturing only the changes since the last backup would reduce storage requirements and backup time. Data Recovery: Facilitating point-in-time recovery by replaying captured changes to restore a database to a specific state.
- ETL (Extract, Transform, Load): When ETL pipelines are integrated with CDC, this can ensure target datastores (data warehouses or data lakes) are updated in (near) real-time. This results in fresher and more relevant data for downstream uses
- Event Sourcing: Event driven architectures can be enabled by using CDC to create event streams.
- Auditing and Compliance: A detailed log of chagnes can also help with regulatory compliance and audit requirements. Tracking the origin and transformation of data over time to understand its lifecycle and maintain data quality is also possible with CDC.
- Real-Time Analytics: CDC can help provide up-to-date data for real-time analytics and dashboards. This would help businesses to make informed decisions based on the latest information.
- And others like incremental monitoring/alerting, updates to ML/AI models with latest data, and more.
Challenges
While the above setup is intuitive there are a few consistency and timeliness challenges:
- Replication slots only capture changes from the point they were "setup". So if the RS was not setup at the time of the database's creation the reader/poller will only have access to partial change events. If such a system is used to replicate data only partial replication is possible.
- In order to ensure that "current source state" is captured before any events are emitted, a full snapshot of the source is required so that the output is in a consistent "current" state before the poller starts reading and processing CDC events.
- Doing a full snapshot of the (source) database is a very expensive and restrictive process. When a snapshot is taking place, writes to the database must be prevented. It is very impractical to prevent writes in a live (and high scale) system.
Proposal
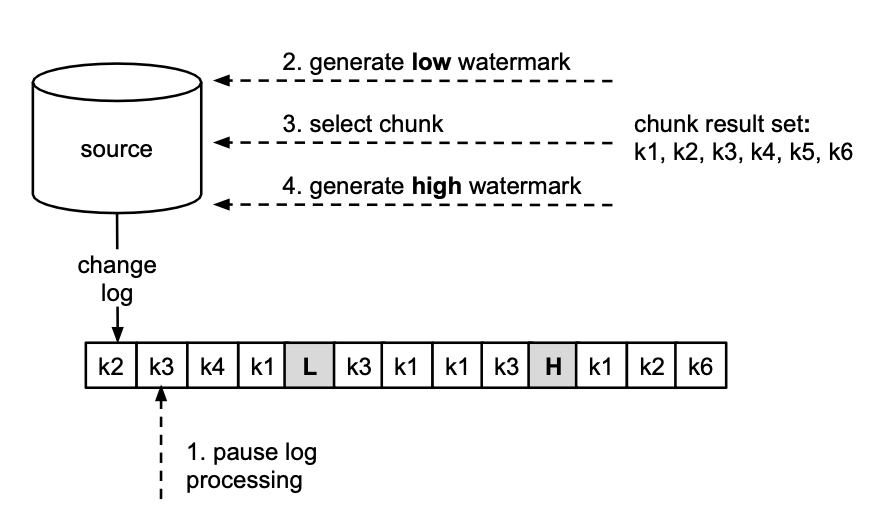
Thankfully DBLog offers a very elegant and incremental solution to the above problem. Briefly the DBLog idea uses a low and high watermark based approach to capture the full state of a databse while interleaving events in the transaction log. By doing so the imact on the source database is minimized. Briefly the basic idea is:
- The reader is updated so it can be requested to "pause" and "resume" its polling of the replication slot and processing of the events.
- The reader is first paused to initiate a "snapshot" of a subset of records (this size can be chosen based on load constraints).
- When the reader is in "paused" state, it is requested to "select" a set of records. For these records the database already has the freshest values so the intent is that the reader is to process the latest values for these records. After this selection, the output is guaranteed to have the freshest valeus for the records selected in this set.
- When asked to "select", it first emits a "low watermark" event in the replication slot, performs the "select" of records from the source DB and then emits a "high watermark" event in the replication slot.
- The reader is then requested to resume its polling and processing (of events).
From the paper, this process looks like:
Syncer
This go module is a simple implementation of DBLog. Under the hood it does the following:
- Creates a "control namespace" in the postgresql db being synced.
- In this control namespace, it creates a Watermark table which will be used to induce low/high water mark events in our replication slot.
- Looks for an already created publication for the tables that the user is interested in tracking - this MUST be done by the user/owner of the database. For example if the user is interested in tracking tables
users,restaurants,friends, then a publication must for these tables must be created with the command (whereour_pub_nameis the name of the publication dbsync will be tracking):
CREATE PUBLICATION <our_pub_name> FOR TABLE users, restaurants, friends ;
- Takes the above publication (
our_pub_name) and adds the watermark table to it. This ensures that changes to the watermark table along with the changes to theusers,restaurantsandfriendstables are all serialized to this publication in the order in which the writes were made (to the respective tables). - Once the publication is amended, a replication slot is created (if it does not exist). This replication slot will be ready by the reader/poller going forward.
Getting Started
Before writing/starting your reader, we want to make sure the following are set:
Ensure postgres
Make sure you have postgres running and that its wal_level is set to "logical" (in the postgresql.conf file)
Setup environment variables
The following environment variables (corresponding to your database instance) are set:
- POSTGRES_DB - Name of the Postgres DB to setup replication on
- POSTGRES_HOST - Host where the DB is executing
- POSTGRES_PORT - Port on which the DB is served from
- POSTGRES_USER - Admin username to connect to the postgres db to setup replication on
- POSTGRES_PASSWORD - Password of the admin user
- DEFAULT_DBSYNC_CTRL_NAMESPACE - Sets the name of the control namespace where the watermark table is created. Defaults to
dbsync_ctrl. - DEFAULT_DBSYNC_WM_TABLENAME - Sets the name of the watermark table which will induce low/high watermkark events in our replication slot. Defaults to
dbsync_wmtable. - DEFAULT_DBSYNC_PUBNAME - Name of the publication that will be altered to add the watermark table to. This MUST be created by the user/admin of the database for the tables they are interested in syncing. Defaults to
dbsync_mypub. - DEFAULT_DBSYNC_REPLSLOT - Name of the replication slot that will be created (over the publication). Defaults to
dbsync_replslot.
Examples
Simple change logger
In our basic example we simply log changes to the stdout:
func main() {
// Assuming you have created the publication over the tables to be tracked
d, err := dbsync.NewSyncer()
if err != nil {
panic(err)
}
d.MessageHandler = &dbsync.EchoMessageHandler{}
d.Start()
}
Start your postgres db (with defaults), and as you update tables (selected for event publication) you will see the events printed on stdout.
Custom message processing based on event type
Instead of printing every message, we can treat each message type in a custom manner. Since DefaultMessageHandler has a no-op for all of the MessageHandler methods, it can be included in our custom handler - the OurMessageHandler, while only overriding messages we are interested in:
func main() {
// Assuming you have created the publication over the tables to be tracked
d, err := dbsync.NewSyncer()
if err != nil {
panic(err)
}
d.MessageHandler = &OurMessageHandler{}
d.Start()
}
type OurMessageHandler struct {
dbsync.DefaultMessageHandler
}
// Specialized insert message handler
func (h *OurMessageHandler) HandleInsertMessage(m *dbsync.DefaultMessageHandler, idx int, msg *pglogrepl.InsertMessage, reln *pglogrepl.RelationMessage) error {
log.Println("Handling Insert Message: ", idx, msg, reln)
// ... process a record creation - eg create the record in the secondary index
return nil
}
// Specialized delete message handler
func (h *OurMessageHandler) HandleDeleteMessage(m *dbsync.DefaultMessageHandler, idx int, msg *pglogrepl.DeleteMessage, reln *pglogrepl.RelationMessage, tableInfo *PGTableInfo) error {
log.Println("Handling Delete Message: ", idx, msg, reln)
// ... process a record deletion - eg delete from a secondary index
return nil
}
// Specialized update message handler
func (h *OurMessageHandler) HandleUpdateMessage(m *dbsync.DefaultMessageHandler, idx int, msg *pglogrepl.UpdateMessage, reln *pglogrepl.RelationMessage) error {
log.Println("Handling Updated Message: ", idx, msg, reln)
// ... process a record update - eg write to a secondary index
return nil
}
Batch processing messages with event compaction
Consider the case where in a short period of time as messages are read from the replication slot most updates are for a small set of frequent keys, eg:
1. Update K1
2. Delete K1
3. Create K1
4. Update K2
5. Update K2
6. Update K2
7. Insert K3
8. Delete K2
9. Insert K2
10. Delete K1
In this scenario, if messages were processed one at a time so that they are replicated to another store we would need a total of 10 writes (on the target datastore). Instead these messages can be compacted so that only the final state of the affected records are written in one go. This ensures that a key's final state is recorded instead of all its intermediate states. For example after doing 4 writes on key K1, its finally deleted.
Syncer provides a few primitives to ensure that events are compacted and writes are minimized via batching.
MarkAsUpdatedandMarkAsDeletedmethods that can be called by the message handler (on Syncer) to so that the final state of a key is actively tracked.Batcherinterface to perform batch updates and batch deletions on a collection of records
Using this our example is now:
func main() {
// Assuming you have created the publication over the tables to be tracked
d, err := dbsync.NewSyncer()
if err != nil {
panic(err)
}
d.MessageHandler = &OurMessageHandler{ds: d}
d.Batcher = &EchoBatcher{}
d.Start()
}
type OurMessageHandler struct {
dbsync.DefaultMessageHandler
ds *Syncer
}
func (d *OurMessageHandler) HandleInsertMessage(idx int, msg *pglogrepl.InsertMessage, reln *pglogrepl.RelationMessage) error {
log.Println("Handling Insert Message: ", idx, msg, reln)
recordType := // Get record type for message
recordId := // Get ID for the record
recordValue := // compute record's value to be passed to our batcher - for example if we are writing to a key/value store,
// this value would be the document format appropriate for the key value store
d.ds.MarkAsUpdated(recordType, recordId, recordValue)
return nil
}
func (d *OurMessageHandler) HandleDeleteMessage(idx int, msg *pglogrepl.DeleteMessage, reln *pglogrepl.RelationMessage, tableInfo *PGTableInfo) error {
log.Println("Handling Delete Message: ", idx, msg, reln)
recordType := // Get record type for message
recordId := // Get ID for the record
d.ds.MarkAsDeleted(recordType, recordId)
return nil
}
func (d *OurMessageHandler) HandleUpdateMessage(idx int, msg *pglogrepl.UpdateMessage, reln *pglogrepl.RelationMessage) error {
log.Println("Handling Updated Message: ", idx, msg, reln)
recordType := // Get record type for message
recordId := // Get ID for the record
recordValue := // compute record's value to be passed to our batcher - for example if we are writing to a key/value store,
// this value would be the document format appropriate for the key value store
d.ds.MarkAsUpdated(recordType, recordId, recordValue)
return nil
}
Unlike the individual message processing example, here the record type, ID and values are extracted from the change capture event and prepared/converted to a format suitable to the target store (eg if records are to be replicated into elastic, then recordValue will be the final document that elastic might accept). Similary when messages are deleted, all deleted records are collected for a batch deletion later on.
This brings us to the Batched writes. Syncer can accept a Batcher instance of the type:
type Batcher interface {
BatchUpsert(doctype string, docs []map[string]any) (any, error)
BatchDelete(doctype string, docids []string) (any, error)
}
Once the processing of events is done, the Batcher can be used to upsert documents that were marked for udpates and delete documents marked for deletions in one fell swoop. Our Batcher implementation could simply be one that writes the collected documents to stdout:
type EchoBatcher struct {}
func (e *EchoBatcher) BatchUpsert(doctype string, docs []map[string]any) (any, error) {
log.Println("Upserting items for doctype: ", doctype)
for k,_ := range docs {
log.Println("Updating document with id: ", k)
}
}
func (e *EchoBatcher) BatchDelete(doctype string, docids []string) (any, error) {
log.Println("Deleting items for doctype: ", doctype, docids)
}
Inducing partial snapshots
So far we have been on the happy path where - the replication slots were setup before any writes were incurred on the tables being monitored. However from time to time forcing a reload of certain keys (or key ranges) is needed - if nothing else then to simply refresh them. Simply loading the records with keys (of interest) wont do. Because while selecting the records and processing them, there could be other writes to these entities that may be missed or be out-of-band resulting in inconsistent data. Here is where the original DBLog idea shines. Please do read it and understand it. The details wont be covered here, only our interface providing the functionality.
In order to perform a partial reload/refresh of data, Syncer exposes a "Refresh" method:
func (d *Syncer) Refresh(selectQuery string)
This method performs the record selection and performs the heart of the DBLog algorithm by performing non-stale reads and using low/high watermarks to bound this selection. This ensures that entries matched by the selectQuery (a SELECT statement with filters) are processed in a consistent freshness preserving manner.