# README
SQL wrapper code generator for MySQL

![]()
sqlw-mysql is a CLI tool to generate go wrapper code (or any text source) for your MySQL database and queries.
Table of Contents
- Install
- Design/Goals/Features
- Motivation
- Quickstart
- Statement XML
- Template
- Command line options
- Licence
Install
$ GO111MODULE=on go get -u github.com/huangjunwen/sqlw-mysql
Design/Goals/Features
- Not an
ORM, but provide similar features. - Database first,
sqlw-mysqlgenerate wrapper code for your database tables. - Use XML as DSL to describe query statements,
sqlw-mysqlgenerate wrapper code for them. - Should be work for all kinds of queries, from simple ones to complex ones.
- Highly customizable template. Can be used to generate wrapper code but also any text source.
- Extensible DSL (through directives).
Motivation
See my blog post for this project (in Chinese): 写了一个 MySQL 数据表和查询的 go 代码生成器
Quickstart
Let's start with a small example. (See here for complete source code)
Suppose you have a database with two tables: user and employee; An employee must be a user, but a user need not to be an employee; Each employee must have a superior except those top dogs.
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(64) NOT NULL,
`female` tinyint(1) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `employee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`employee_sn` char(32) NOT NULL,
`user_id` int(11) NOT NULL,
`superior_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `employee_sn` (`employee_sn`),
UNIQUE KEY `user_id` (`user_id`),
KEY `superior_id` (`superior_id`),
CONSTRAINT `fk_superior` FOREIGN KEY (`superior_id`) REFERENCES `employee` (`id`),
CONSTRAINT `fk_user` FOREIGN KEY (`user_id`) REFERENCES `user` (`id`)
);
Now run sqlw-mysql. You will see a models directory is created with several source files generated:
$ sqlw-mysql -dsn "user:passwd@tcp(host:port)/db?parseTime=true"
$ ls ./models
... table_user.go ... table_employee.go
Especially, a table_<table name>.go is generated for each table containing structs/methods for some common single table operations:
// ./models/table_user.go
// User represents a row of table `user`.
type User struct {
Id int32 `json:"id" db:"id"`
Name string `json:"name" db:"name"`
Female null.Bool `json:"female" db:"female"`
Birthday null.Time `json:"birthday" db:"birthday"`
}
func (tr *User) Insert(ctx context.Context, e Execer) error {
// ...
}
func (tr *User) Reload(ctx context.Context, q Queryer) error {
// ...
}
But eventually, you will need more complex quries. For example if you want to query all user and its associated employee (e.g. one2one relationship), then you can write a statement XML like this:
<!-- ./stmts/user.xml -->
<stmt name="AllUserEmployees">
SELECT
<wc table="user" />,
CAST(DATEDIFF(NOW(), birthday)/365 AS UNSIGNED) AS age,
<wc table="employee" as="empl" />
FROM
user LEFT JOIN employee AS empl ON user.id=empl.user_id
</stmt>
A statement XML contains SQL statement with special directives embeded in. Here you can see two <wc table="table_name"> directives, which are roughly equal to expanded table_name.*.
See Statement XML for detail.
Now run sqlw-mysql again with the statement XML directory:
$ sqlw-mysql -dsn "user:passwd@tcp(host:port)/db?parseTime=true" -stmt ./stmts
$ ls ./models
... table_user.go ... table_employee.go ... stmt_user.go
A new file stmt_user.go is generated from user.xml:
// ./models/stmt_user.go
// AllUserEmployeesResult is the result of AllUserEmployees.
type AllUserEmployeesResult struct {
User *User
Age null.Uint64
Empl *Employee
nxNullUser nxNullUser
nxNullEmpl nxNullEmployee
}
// AllUserEmployeesResultSlice is slice of AllUserEmployeesResult.
type AllUserEmployeesResultSlice []*AllUserEmployeesResult
// ...
func AllUserEmployees(ctx context.Context, q Queryer) (AllUserEmployeesResultSlice, error) {
// ...
}
Notice that User and Empl fields in result struct are generated from those <wc> directives. sqlw-mysql is smart enough to figure out their correct positions. See here for detail.
Now you can use the newly created function to iterate through all user and employee:
slice, err := models.AllUserEmployees(ctx, tx)
if err != nil {
log.Fatal(err)
}
for _, result := range slice {
user := result.User
empl := result.Empl
if empl.Valid() {
log.Printf("User %+q (age %d) is an employee, sn: %+q\n", user.Name, result.Age.Uint64, empl.EmployeeSn)
} else {
log.Printf("User %+q (age %d) is not an employee\n", user.Name, result.Age.Uint64)
}
}
Another example, if you want to find subordinates of some employees (e.g. one2many relationship):
<!-- ./stmts/user.xml -->
<stmt name="SubordinatesBySuperiors">
<a name="id" type="...int" />
<v in_query="1" />
SELECT
<wc table="employee" as="superior" />,
<wc table="employee" as="subordinate" />
FROM
employee AS superior LEFT JOIN employee AS subordinate ON subordinate.superior_id=superior.id
WHERE
superior.id IN (<b name="id"/>)
</stmt>
Brief explanation about new directives:
<a>specifies an argument of the generated function.<v>specifies arbitary variables that the template can use.in_query="1"tells the template that the SQL useINoperator.<b>argument binding.
See Directives for detail.
After re-running the command, the following code is generated:
// ./models/stmt_user.go
// SubordinatesBySuperiorsResult is the result of SubordinatesBySuperiors.
type SubordinatesBySuperiorsResult struct {
Superior *Employee
Subordinate *Employee
nxNullSuperior nxNullEmployee
nxNullSubordinate nxNullEmployee
}
// SubordinatesBySuperiorsResultSlice is slice of SubordinatesBySuperiorsResult.
type SubordinatesBySuperiorsResultSlice []*SubordinatesBySuperiorsResult
// ...
func SubordinatesBySuperiors(ctx context.Context, q Queryer, id ...int) (SubordinatesBySuperiorsResultSlice, error) {
// ...
}
Then, you can iterate the result like:
slice, err := models.SubordinatesBySuperiors(ctx, tx, 1, 2, 3, 4, 5, 6, 7)
if err != nil {
log.Fatal(err)
}
superiors, groups := slice.GroupBySuperior()
for i, superior := range superiors {
subordinates := groups[i].DistinctSubordinate()
if len(subordinates) == 0 {
log.Printf("Employee %+q has no subordinate.\n", superior.EmployeeSn)
} else {
log.Printf("Employee %+q has the following subordinates:\n", superior.EmployeeSn)
for _, subordinate := range subordinates {
log.Printf("\t%+q\n", subordinate.EmployeeSn)
}
}
}
In fact, sqlw-mysql doesn't care about what kind of relationships between result fields. It just generate helper methods such as GroupByXXX/DistinctXXX for these fields, thus it works for all kinds of relationships.
Statement XML
sqlw-mysql use XML as DSL to describe quries, since XML is suitable for mixed content: raw SQL query and special directives.
The simplest one is a <stmt> element with name attribute, without any directive, like this:
<stmt name="One">
SELECT 1
</stmt>
But this is not very useful, sometimes we want to add meta data to it, sometimes we want to reduce verbosity ...
That's why we need directives:
Directives
Directive represents a fragment of SQL query, usually declared by an XML element. sqlw-mysql processes directives in several passes:
- The first pass all directives should generate fragments that form a valid SQL statement (e.g.
SELECT * FROM user WHERE id=1). This SQL statement is then used to determine statement type, to obtain result column information by querying the database if it's a SELECT. - The second pass all directives should generate fragments that form a text statement for template renderring (e.g.
SELECT * FROM user WHERE id=:id). It's no need to be a valid SQL statement, it's up to the template to decide how to use this text. - Some directives may run extra pass.
The following are a list of current builtin directives. In future new directives may be added. And should be easy enough to implement one: impelemnts a go interface.
Arg directive
- Name:
<arg>/<a> - Example:
<a name="id" type="int" /> - First pass result:
"" - Second pass result:
""
Declare a wrapper function argument's name and type. Always returns empty string.
Vars directive
- Name:
<vars>/<v> - Example:
<v flag1="true" flag2="true" /> - First pass result:
"" - Second pass result:
""
Declare arbitary key/value pairs (XML attributes) for template to use. Always returns empty string.
Replace directive
- Name:
<repl>/<r> - Example:
<r by=":id">1</r> - First pass result:
"1" - Second pass result:
":id"
Returns the inner text for the first pass and returns the value in by attribute for the second pass.
Bind directive
- Name:
<bind>/<b> - Example:
<b name="id" />or<b name="limit">10</b> - First pass result:
"NULL"or inner text of<b>element. - Second pass result:
":id"
<b name="xxx" /> is equivalent to <r by=":xxx">NULL</r> and <b name="xxx">val</b> is equivalent to <r by=":xxx">val</r>. And the bind name must be an argument name.
NOTE: NULL is not allowed in some clause in MySQL. For example:
SELECT * FROM user LIMIT NULL -- Invalid
Thus if you want to bind an argument in the LIMIT clause, you have to write a number explicitly:
LIMIT <b name="limit">1</b>
Text directive
- Name:
<text>/<t> - Example:
<t>{{ if ne .id 0 }}</t> - First pass result:
"" - Second pass result:
"{{ if ne .id 0 }}"
<t>innerText</t> is equivalent to <r by="innerText"></r>.
Wildcard directive
- Name:
<wc> - Example:
<wc table="employee" as="empl" /> - First pass result:
"`empl`.`id`, ..., `empl`.`superior_id`" - Second pass result:
"`empl`.`id`, ..., `empl`.`superior_id`"
Returns the expanded column list of the table. It runs an extra pass to determine fields positions, see here for detail.
How wildcard directive works
<wc> (wildcard) directive serves several purposes:
- Reduce verbosity, also it's a 'safer' version of
table.*(It expands all columns of the table). - Figure out the positions of these expanded columns so that template can make use of.
In the extra pass of <wc> directives, special marker columns are added before and after each <wc> directive, for example:
SELECT NOW(), <wc table="user" />, NOW() FROM user
will be expanded to something like:
SELECT NOW(), 1 AS wc456958346a616564_0_s, `user`.`id`, ..., `user`.`birthday`, 1 AS wc456958346a616564_0_e, NOW() FROM user
By finding these marker column name in the result columns, sqlw-mysql can determine their positions.
This even works for subquery:
SELECT * FROM (SELECT <wc table="user" /> FROM user) AS u
And if you only selects a single column (or a few columns) like:
SELECT birthday FROM (SELECT <wc table="user" /> FROM user) AS u
Then the wildcard directive is ignored since you're not selecting all columns of the table.
Template
sqlw-mysql itself only provides information extracted from database/DSL. Most features are in fact implemented in template. A template is a directory looks like:
$ tree default
default
├── interface.go.tmpl
├── manifest.json
├── meta.go.tmpl
├── meta_test.go.tmpl
├── scan_type_map.json
├── stmt_{{.StmtXMLName}}.go.tmpl
├── table_{{.Table.TableName}}.go.tmpl
└── util.go.tmpl
A manifest.json contains lists of templates to render and other customizable information:
{
"scanTypeMap": "scan_type_map.json",
"perRun": [
"interface.go.tmpl",
"meta.go.tmpl",
"util.go.tmpl",
"meta_test.go.tmpl"
],
"perTable": [
"table_{{.Table.TableName}}.go.tmpl"
],
"perStmtXML": [
"stmt_{{.StmtXMLName}}.go.tmpl"
]
}
manifest["scanTypeMap"] is used to map database type (key) to go scan type (value, value[0] is for NOT nullable type and value[1] is for nullable type):
{
"bool": ["bool", "null.Bool"],
"int8": ["int8", "null.Int8"],
"uint8": ["uint8", "null.Uint8"],
"int16": ["int16", "null.Int16"],
"uint16": ["uint16", "null.Uint16"],
"int32": ["int32", "null.Int32"],
"uint32": ["uint32", "null.Uint32"],
"int64": ["int64", "null.Int64"],
"uint64": ["uint64", "null.Uint64"],
"float32": ["float32", "null.Float32"],
"float64": ["float64", "null.Float64"],
"time": ["time.Time", "null.Time"],
"decimal": ["string", "null.String"],
"bit": ["string", "null.String"],
"json": ["string", "null.String"],
"string": ["string", "null.String"]
}
manifest["perRun"] list templates to render once per run. manifest["perTable"] list templates to render once per database table. manifest["perStmtXML"] list templates to render once per statement xml file.
sqlw-mysql templates can use functions provided by sprig, checkout func.go to see the full list of supported functions.
Default template
If no custom template specified, or -tmpl @default is given, then the default template is used.
Genreated code depends on these external libraries:
- sqlx.
- sqlboiler's null-extended package.
For statement XML, the default template accept these <vars>:
| Name | Example | Note |
|---|---|---|
use_template | use_template="1" | If presented, then the statement text is treated as a go template |
in_query | in_query="1" | If presented, then statement will do an "IN" expansion, see http://jmoiron.github.io/sqlx/#inQueries |
return | return="one" | For SELECT statement only, by default the generated function returns a slice, if return="one", then returns a single item instead |
An example of use_template:
<stmt name="UsersByCond">
<v use_template="1" />
<a name="id" type="int" />
<a name="name" type="string" />
<a name="birthday" type="time.Time" />
<a name="limit" type="int" />
SELECT
<wc table="user" />
FROM
user
WHERE
<t>{{ if ne .id 0 }}</t>
id=<b name="id"/> AND
<t>{{ end }}</t>
<t>{{ if ne (len .name) 0 }}</t>
name=<b name="name"/> AND
<t>{{ end }}</t>
<t>{{ if not .birthday.IsZero }}</t>
birthday=<b name="birthday"/> AND
<t>{{ end }}</t>
1
LIMIT <b name="limit">10</b>
</stmt>
Then the generated statement will be treated as a go template and will be renderred before normal execution. This is useful when you have many WHERE condtions combination.
If enviroment "CAMEL_JSON_KEY" is given, than json tags of structs generated will be use lower camel case such as "createdAt".
Graphviz template
sqlw-mysql can be used to generate other text source as well. For example running with -tmpl @graphviz a .dot file will be generated containing tables and their relationships, which can be convert to a diagram like this:
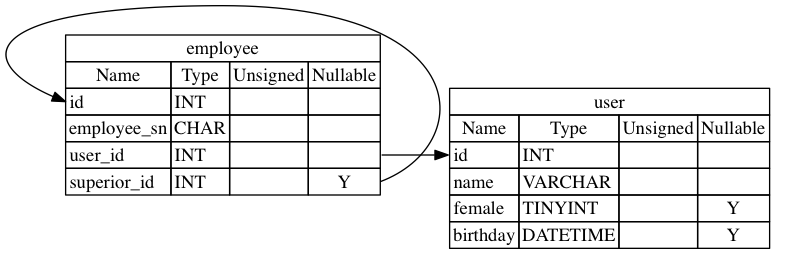
Command line options
$ sqlw-mysql -h
Usage of sqlw-mysql:
-blacklist value
(Optional) Comma separated table names not to render.
-dsn string
(Required) Data source name. e.g. "user:passwd@tcp(host:port)/db?parseTime=true"
-out string
(Optional) Output directory for generated code. (default "models")
-pkg string
(Optional) Alternative package name of the generated code.
-stmt string
(Optional) Statement xmls directory.
-tmpl string
(Optional) Custom templates directory. Or use '@name' to use the named builtin template.
-whitelist value
(Optional) Comma separated table names to render.
Licence
MIT
Author: huangjunwen ([email protected])