# Packages
# README

work
A compact library for tracking and committing atomic changes to your entities.
![]()
![]()
![]()

![]()
Demo
make demo (requires docker-compose).
How to use it?
Construction
Starting with entities Foo and Bar,
// entities.
f, b := Foo{}, Bar{}
// type names.
ft, bt := unit.TypeNameOf(f), unit.TypeNameOf(b)
// data mappers.
m := map[unit.TypeName]unit.DataMapper { ft: fdm, bt: fdm }
// 🎉
opts = []unit.Option{ unit.DB(db), unit.DataMappers(m) }
unit, err := unit.New(opts...)
Adding
When creating new entities, use Add:
additions := []interface{}{ f, b }
err := u.Add(additions...)
Updating
When modifying existing entities, use Alter:
updates := []interface{}{ f, b }
err := u.Alter(updates...)
Removing
When removing existing entities, use Remove:
removals := []interface{}{ f, b }
err := u.Remove(removals...)
Registering
When retrieving existing entities, track their intial state using
Register:
fetched := []interface{}{ f, b }
err := u.Register(fetched...)
Saving
When you are ready to commit your work unit, use Save:
ctx := context.Background()
err := u.Save(ctx)
Logging
We use zap as our logging library of choice. To leverage the logs
emitted from the work units, utilize the unit.Logger
option with an instance of *zap.Logger upon creation:
// create logger.
l, _ := zap.NewDevelopment()
opts = []unit.Option{
unit.DB(db),
unit.DataMappers(m),
unit.Logger(l), // 🎉
}
u, err := unit.New(opts...)
Metrics
For emitting metrics, we use tally. To utilize the metrics emitted
from the work units, leverage the unit.Scope option
with a tally.Scope upon creation. Assuming we have a
scope s, it would look like so:
opts = []unit.Option{
unit.DB(db),
unit.DataMappers(m),
unit.Scope(s), // 🎉
}
u, err := unit.New(opts...)
Emitted Metrics
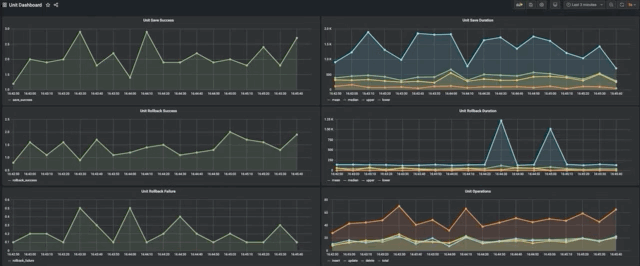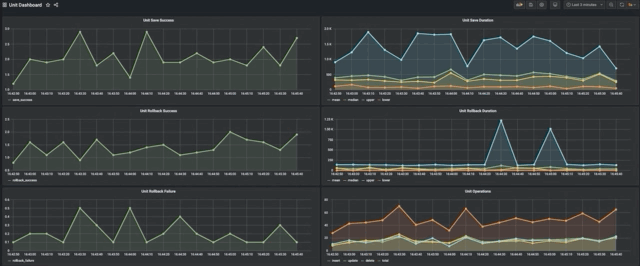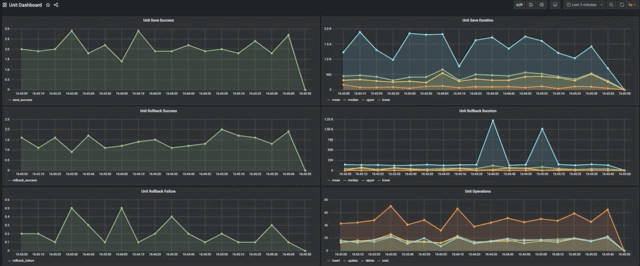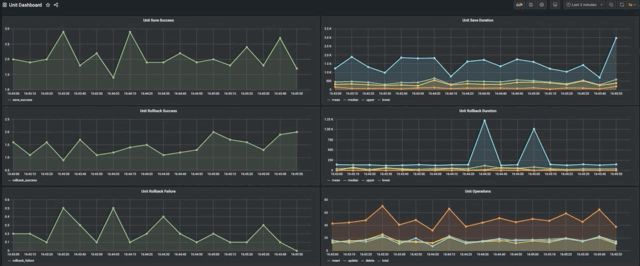
| Name | Type | Description |
|---|---|---|
| [PREFIX.]unit.save.success | counter | The number of successful work unit saves. |
| [PREFIX.]unit.save | timer | The time duration when saving a work unit. |
| [PREFIX.]unit.rollback.success | counter | The number of successful work unit rollbacks. |
| [PREFIX.]unit.rollback.failure | counter | The number of unsuccessful work unit rollbacks. |
| [PREFIX.]unit.rollback | timer | The time duration when rolling back a work unit. |
| [PREFIX.]unit.retry.attempt | counter | The number of retry attempts. |
| [PREFIX.]unit.insert | counter | The number of successful inserts performed. |
| [PREFIX.]unit.update | counter | The number of successful updates performed. |
| [PREFIX.]unit.delete | counter | The number of successful deletes performed. |
| [PREFIX.]unit.cache.insert | counter | The number of registered entities inserted into the cache. |
| [PREFIX.]unit.cache.delete | counter | The number of registered entities removed from the cache. |
Uniters
In most circumstances, an application has many aspects that result in the
creation of a work unit. To tackle that challenge, we recommend using
unit.Uniter to create instances of unit.,
like so:
opts = []unit.Option{
unit.DB(db),
unit.DataMappers(m),
unit.Logger(l),
}
uniter := unit.NewUniter(opts...)
// create the unit.
u, err := uniter.Unit()
Frequently Asked Questions (FAQ)
Are batch data mapper operations supported?
In short, yes.
A work unit can accommodate an arbitrary number of entity types. When creating the work unit, you indicate the data mappers that it should use when persisting the desired state. These data mappers are organized by entity type. As such, batching occurs for each operation and entity type pair.
For example, assume we have a single work unit and have performed a myriad
of unit operations for entities with either a type of Foo or Bar. All inserts
for entities of type Foo will be passed to the corresponding data mapper in
one shot via the Insert method. This essentially then relinquishes control to you,
the author of the data mapper, to handle all of those entities to be inserted
in however you see fit. You could choose to insert them all into a relational
database using a single INSERT query, or perhaps issue an HTTP request to
an API to create all of those entities. However, inserts for entities of type
Bar will be batched separately. In fact, it's most likely the data mapper to handle
inserts for Foo and Bar are completely different types (and maybe even
completely different data stores).
The same applies for other operations such as updates and deletions. All supported data mapper operations follow this paradigm.