# Packages
# README
Goptuna
![]()

Decentralized hyperparameter optimization framework, inspired by Optuna [1]. This library is particularly designed for machine learning, but everything will be able to optimize if you can define the objective function (e.g. Optimizing the number of goroutines of your server and the memory buffer size of the caching systems).
Supported algorithms:
Goptuna supports various state-of-the-art Bayesian optimization, evolution strategies and Multi-armed bandit algorithms. All algorithms are implemented in pure Go and continuously benchmarked on GitHub Actions.
- Random search
- TPE: Tree-structured Parzen Estimators [2]
- CMA-ES: Covariance Matrix Adaptation Evolution Strategy [3]
- IPOP-CMA-ES: CMA-ES with increasing population size [4]
- BIPOP-CMA-ES: BI-population CMA-ES [5]
- Median Stopping Rule [6]
- ASHA: Asynchronous Successive Halving Algorithm (Optuna flavored version) [1,7,8]
- Quasi-monte carlo sampling based on Sobol sequence [10, 11]
Projects using Goptuna:
- Kubeflow/Katib: Kubernetes-based system for hyperparameter tuning and neural architecture search.
- c-bata/goptuna-bayesopt: Goptuna sampler for Gaussian Process based bayesian optimization using d4l3k/go-bayesopt. [9]
- c-bata/goptuna-isucon9q: Applying bayesian optimization for the parameters of MySQL, Nginx and Go web applications.
- (If you have a project which uses Goptuna and want your own project to be listed here, please submit a GitHub issue.)
Installation
You can integrate Goptuna in wide variety of Go projects because of its portability of pure Go.
$ go get -u github.com/c-bata/goptuna
Usage
Goptuna supports Define-by-Run style API like Optuna. You can dynamically construct the search spaces.
Basic usage
package main
import (
"log"
"math"
"github.com/c-bata/goptuna"
"github.com/c-bata/goptuna/tpe"
)
// ① Define an objective function which returns a value you want to minimize.
func objective(trial goptuna.Trial) (float64, error) {
// ② Define the search space via Suggest APIs.
x1, _ := trial.SuggestFloat("x1", -10, 10)
x2, _ := trial.SuggestFloat("x2", -10, 10)
return math.Pow(x1-2, 2) + math.Pow(x2+5, 2), nil
}
func main() {
// ③ Create a study which manages each experiment.
study, err := goptuna.CreateStudy(
"goptuna-example",
goptuna.StudyOptionSampler(tpe.NewSampler()))
if err != nil { ... }
// ④ Evaluate your objective function.
err = study.Optimize(objective, 100)
if err != nil { ... }
// ⑤ Print the best evaluation parameters.
v, _ := study.GetBestValue()
p, _ := study.GetBestParams()
log.Printf("Best value=%f (x1=%f, x2=%f)",
v, p["x1"].(float64), p["x2"].(float64))
}
Link: Go Playground
Furthermore, I recommend you to use RDB storage backend for following purposes.
- Continue from where we stopped in the previous optimizations.
- Scale studies to tens of workers that connecting to the same RDB storage.
- Check optimization results via a built-in dashboard.
Built-in Web Dashboard
You can check optimization results by built-in web dashboard.
- SQLite3:
$ goptuna dashboard --storage sqlite:///example.db(See here for details). - MySQL:
$ goptuna dashboard --storage mysql://goptuna:[email protected]:3306/yourdb(See here for details)
| Manage optimization results | Interactive live-updating graphs |
|---|---|
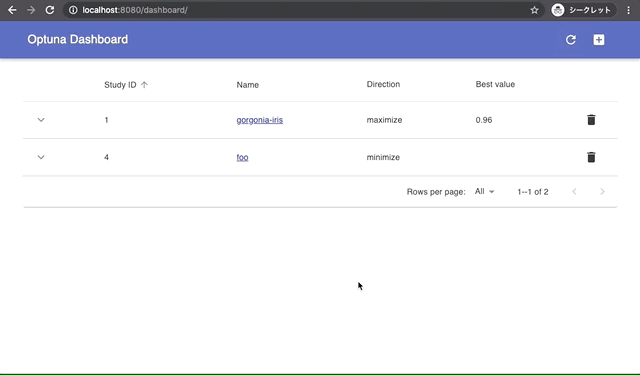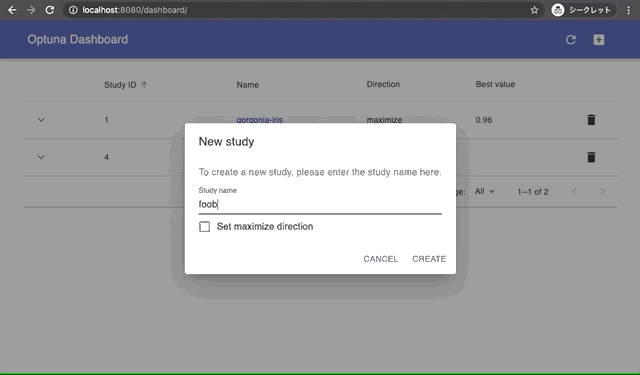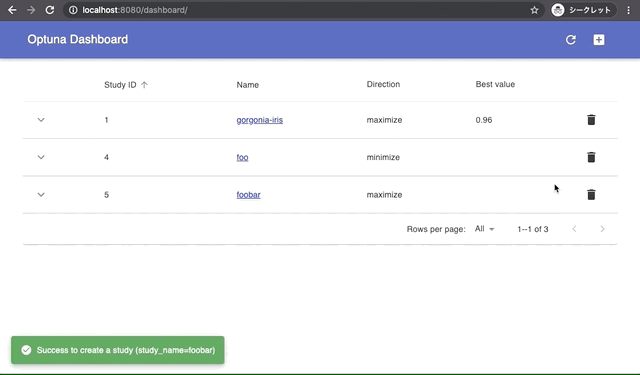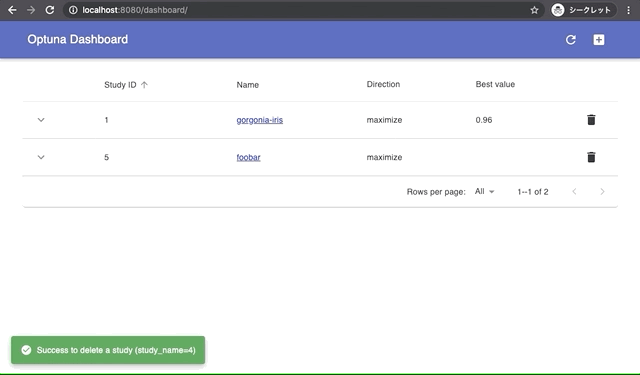 | 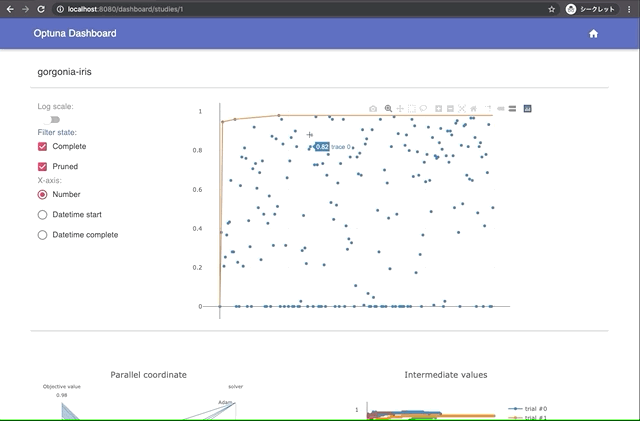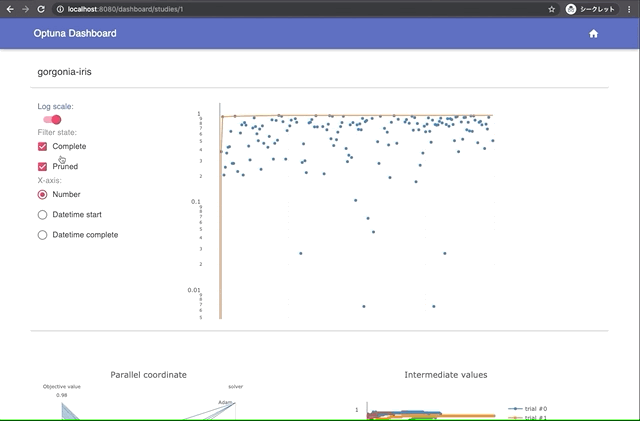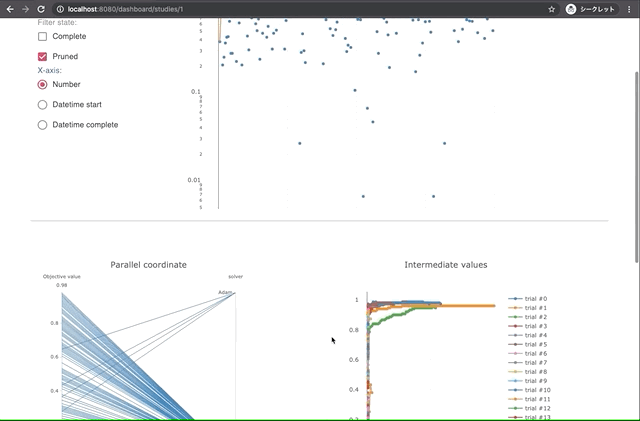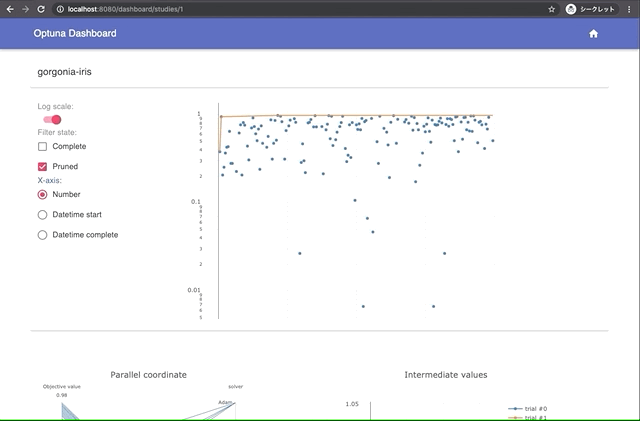 |
Advanced Usage
Parallel optimization with multiple goroutine workers
Optimize method of goptuna.Study object is designed as the goroutine safe.
So you can easily optimize your objective function using multiple goroutine workers.
package main
import ...
func main() {
study, _ := goptuna.CreateStudy(...)
eg, ctx := errgroup.WithContext(context.Background())
study.WithContext(ctx)
for i := 0; i < 5; i++ {
eg.Go(func() error {
return study.Optimize(objective, 100)
})
}
if err := eg.Wait(); err != nil { ... }
...
}
Distributed optimization using MySQL
There is no complicated setup to use RDB storage backend. First, setup MySQL server like following to share the optimization result.
$ docker pull mysql:8.0
$ docker run \
-d \
--rm \
-p 3306:3306 \
-e MYSQL_USER=goptuna \
-e MYSQL_DATABASE=goptuna \
-e MYSQL_PASSWORD=password \
-e MYSQL_ALLOW_EMPTY_PASSWORD=yes \
--name goptuna-mysql \
mysql:8.0
Then, create a study object using Goptuna CLI.
$ goptuna create-study --storage mysql://goptuna:password@localhost:3306/yourdb --study yourstudy
yourstudy
$ mysql --host 127.0.0.1 --port 3306 --user goptuna -ppassword -e "SELECT * FROM studies;"
+----------+------------+-----------+
| study_id | study_name | direction |
+----------+------------+-----------+
| 1 | yourstudy | MINIMIZE |
+----------+------------+-----------+
1 row in set (0.00 sec)
Finally, run the Goptuna workers which contains following code. You can execute distributed optimization by just executing this script from multiple server instances.
package main
import ...
func main() {
db, _ := gorm.Open(mysql.Open("goptuna:password@tcp(localhost:3306)/yourdb?parseTime=true"), &gorm.Config{
Logger: logger.Default.LogMode(logger.Silent),
})
storage := rdb.NewStorage(db)
defer db.Close()
study, _ := goptuna.LoadStudy(
"yourstudy",
goptuna.StudyOptionStorage(storage),
...,
)
_ = study.Optimize(objective, 50)
...
}
Full source code is available here.
Receive notifications of each trials
You can receive notifications of each trials via channel. It can be used for logging and any notification systems.
package main
import ...
func main() {
trialchan := make(chan goptuna.FrozenTrial, 8)
study, _ := goptuna.CreateStudy(
...
goptuna.StudyOptionIgnoreObjectiveErr(true),
goptuna.StudyOptionSetTrialNotifyChannel(trialchan),
)
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
err = study.Optimize(objective, 100)
close(trialchan)
}()
go func() {
defer wg.Done()
for t := range trialchan {
log.Println("trial", t)
}
}()
wg.Wait()
if err != nil { ... }
...
}
Links
References:
- [1] T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, Optuna: A Next-generation Hyperparameter Optimization Framework, KDD, 2019.
- [2] J. Bergstra, R. Bardenet, Y. Bengio, and B. Kégl, Algorithms for hyper-parameter optimization. NeurIPS, 2011.
- [3] N. Hansen, The CMA Evolution Strategy: A Tutorial. arXiv:1604.00772, 2016.
- [4] A. Auger and N. Hansen, A restart CMA evolution strategy with increasing population size, CEC, 2005.
- [5] N. Hansen, Benchmarking a BI-Population CMA-ES on the BBOB-2009 Function Testbed, GECCO Workshop, 2009.
- [6] D. Golovin, B. Sonik, S. Moitra, G. Kochanski, J. Karro, and D.Sculley, Google Vizier: A service for black-box optimization. KDD, 2017.
- [7] K. Jamieson and T. Ameet, Non-stochastic best arm identification and hyperparameter optimization, AISTATS, 2016.
- [8] L. Li, K. Jamieson, A. Rostamizadeh, E. Gonina, M. Hardt, B. Recht, and A. Talwalkar, Massively parallel hyperparameter tuning, arXiv:1810.05934, 2018.
- [9] J. Snoek, H. Larochelle, and R. Adams. Practical Bayesian optimization of machine learning algorithms. NeurIPS, 2012.
- [10] S. Joe and F. Y. Kuo, Remark on Algorithm 659: Implementing Sobol's quasirandom sequence generator, ACM Trans, 2003.
- [11] S. Kucherenko, D. Albrecht, and A. Saltelli, Exploring multi-dimensional spaces: A comparison of latin hypercube and quasi monte carlo sampling techniques, arXiv:1505.02350, 2015.
Presentations:
Blog posts:
Status:
License
This software is licensed under the MIT license, see LICENSE for more information.