# README
🚩 laser 一款高性能浏览器爬虫
🚩 lase是一个高性能的浏览器爬虫,支持原生请求解析(native request)和chrome驱动的爬取。可以以超乎想象的速度进行无限自定义深度的爬取以及对表单参数的解析。
🤔 他可以干什么?
1.对一个网站进行完整的爬取,发掘其目录结构,以及所有可以发起请求对表单参数。
2.单纯进行启发式爬取操作,不涉及目录扫描以及目录爆破。
🌟 完善的多线程管理以及chrome实例管理
1.chrome爬虫部分采用动态标签页管理,可以在高并发的情况下积极调度各个tab页面以实现高性能爬虫。
2.chrome爬虫通过监听每个页面发出的request请求,在进行主动爬取的同时捕获各种由目标js自身执行而发起的请求。
3.native爬虫采用html标签解析。按照w3c标准,对html代码中的所有包含外部连接的属性以及表单参数进行提取。
🌈 使用教程:
quick start
直接使用命令
./darwin_arm64 -target https://news.sina.com.cn
⚠️程序最少只需要提供-target参数就可以使用,但是不会保存任何内容,只会在控制台打印输出。如果需要保存表单参数等详细信息,需要保存到本地文件,文件内容才会展示详细信息。
./darwin_arm64 -target https://news.sina.com.cn -file res.json
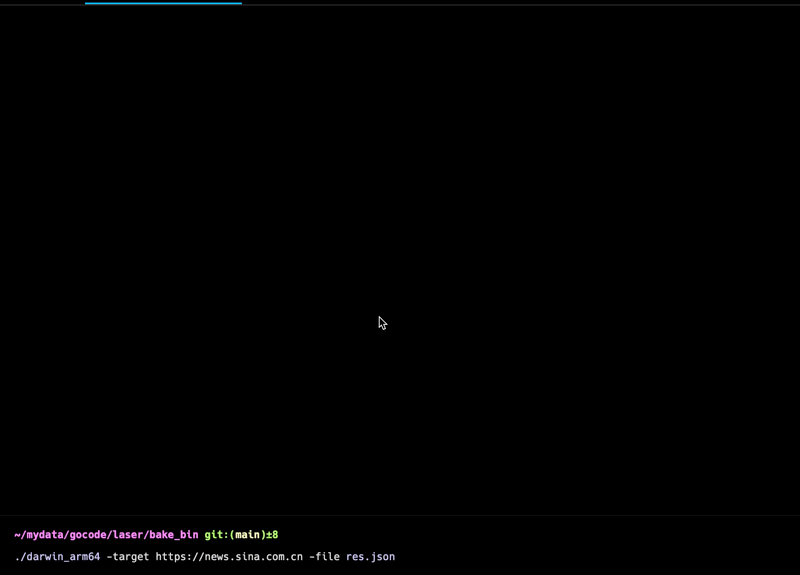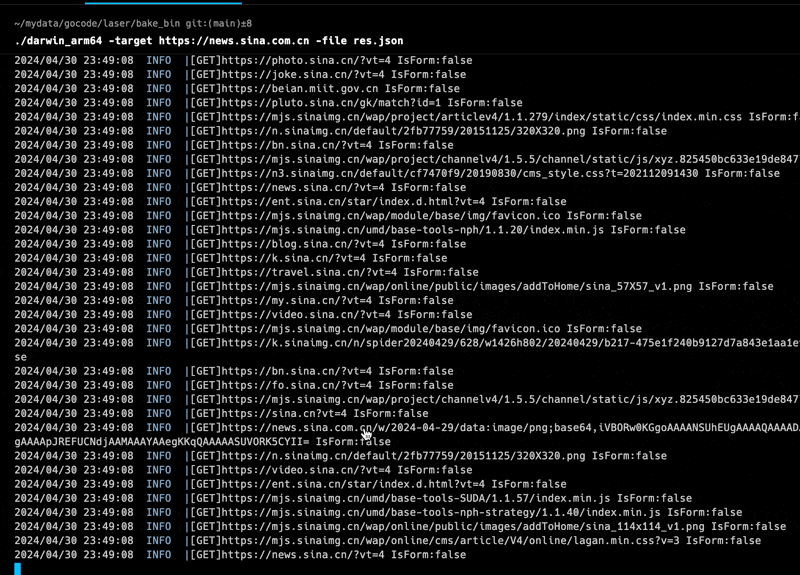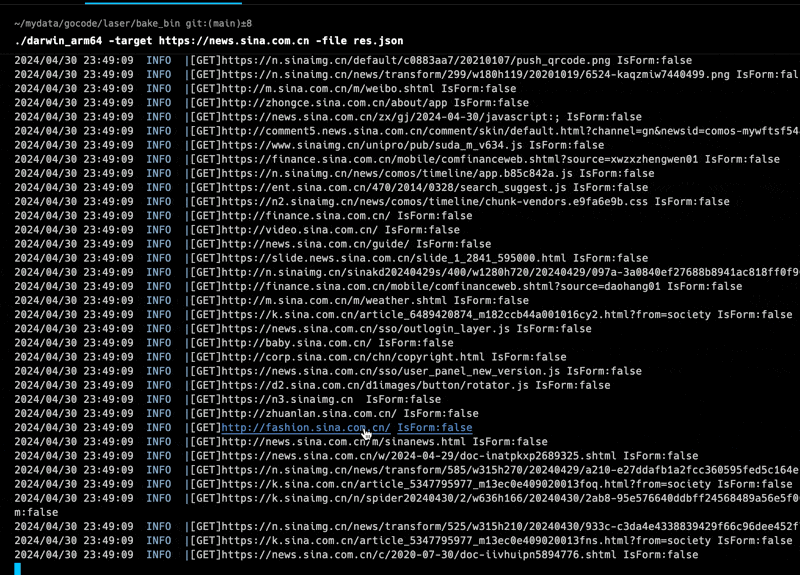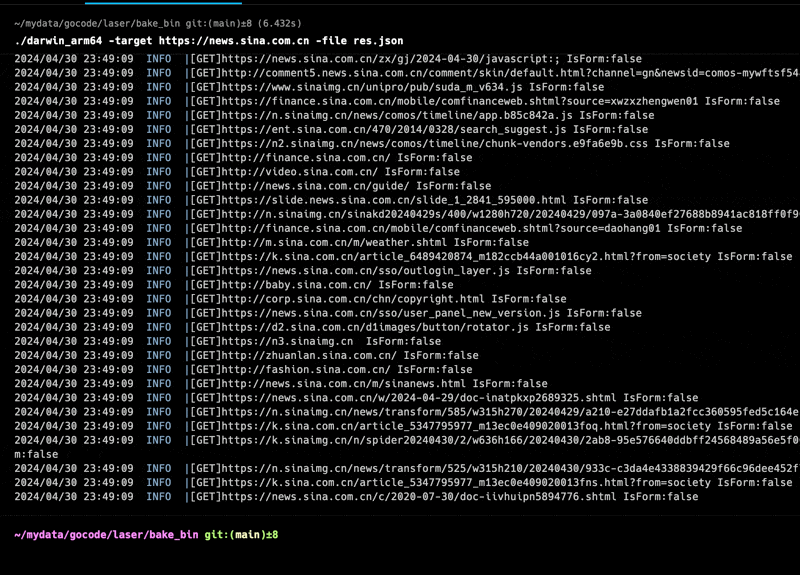
可以看到5s不到就完成了对于https://news.sina.com.cn 深度为2的爬取
产生如下结果
same_originUrl:同源连接,1777条
External_link:外部连接,8960条
external_static_file_link:外部静态资源连接,3143条
same_origin_form:同源提交表单,5个
External_form:外部表单,2个

⭕️ 如果想起用chrome进行爬取,只需要使用如下命令
./darwin_arm64 -target https://news.sina.com.cn -ec
//如果你不想看到浏览器界面,记得启用headless模式
./darwin_arm64 -target https://news.sina.com.cn -ec -headless

完整参数:
